
Profile

|
Jonathon Luiten |
Currently on a research visit to CMU from Sep. 2021 until March 2023 -- Come say hi if you're in Pittsburgh!!!
Looking for my next research job [research scientist, postdoc, faculty] for a start date of April 2023 - get in touch!
Recent News:
- 3 papers accepted at CVPR 2022 (2 as Oral presentations): (1. HODOR, 2. Opening up Open World Tracking, 3. FutureDet)
Education / Employment:
-
Research Visitor at Carnegie Mellon University, USA (2021-current) (Supervisor: Prof. Deva Ramanan)
-
Research Visitor at the University of Oxford, UK (2019-2020) (Supervisor: Prof. Philip Torr)
-
PhD in Computer Science from the RWTH Aachen University, Germany (2018-current) (Supervisor: Prof. Bastian Leibe)
-
Master of Science (MSc) in Simulation Sciences from the RWTH Aachen University, Germany (2016-2018)
-
Bachelor of Engineering (BE) in Engineering Science from the University of Auckland, New Zealand (2013-2016)
Publications:
-
HODOR (CVPR'22 - ORAL) - Video Object Segmentation training on static images.
-
Opening up Open World Tracking (CVPR'22 - ORAL) - Benchmark for tracking objects in an open-world (those never seen in training data).
-
FutureDet (CVPR'22) - Object forecasting as "future object detection", a new way to think about, approach, and evaluate end-to-end forecasting.
-
HOTA Eval Metrics (IJCV'20) - Novel metrics for evaluating multi-object tracking.
-
Single Shot Panoptic Seg (IROS'20) - Fast panoptic segmentation with single-stage networks.
-
Siam R-CNN (CVPR'20) - Object tracking with a two-stage redetector.
-
MOTSFusion (RA-L'20/ICRA'20) - Using 3D object reconstruction to improve tracking.
-
4D-GVT (ICRA'20) - Generic object proposals in video and 3D.
-
UnOVOST (WACV'20) - Unsupervised (zero-shot) video object and instance segmentation.
-
MOTS (CVPR'19) - Simultaneous multi-object tracking and segmentation.
-
Object Mining and Discovery (ICRA'19) - Discovering novel object categories in video corpora.
-
PReMVOS (ACCV'18) - Video object segmentation.
Challenge Results:
-
1st Place YouTubeVIS Challenge 2019 on Video Instance Segmentation (ICCV'19)
-
1st Place DAVIS Challenge 2019 on Unsupervised Video Object Segmentation (CVPR'19)
-
2nd Place DAVIS Challenge 2019 on Semi-Supervised Video Object Segmentation (CVPR'19)
-
1st Place YouTubeVOS Challenge 2018 on Video Object Segmentation (ECCV'18)
-
1st Place DAVIS Challenge 2018 on Video Object Segmentation (CVPR'18)
Workshop Organisation:
-
CVPR'21 Workshop on Robust Video Scene Understanding + The RobMOTS Challenge
-
CVPR'20 Workshop on Multi-Object Tracking and Segmentation (MOTS)
Master Thesis Supervision:
-
Tobias Fischer (MOTSFusion) - Currently: PhD at ETH Zurich with Prof. Fisher Yu
-
Mark Weber (Panoptic Segmentation) - Currently: PhD at TU Munich with Prof. Laura Leal-Taixé
-
Idil Esen Zulfikar (UnOVOST) - Currently: PhD at RWTH Aachen with Prof. Bastian Leibe
-
Thomas Jantos (Panoptic Graph R-CNN) - Currently: PhD at Universität Klagenfurt with Prof. Stephan Weiss
-
Valentin Steiner (Bird’s Eye View Segmentation Datasets)
-
Sourabh Swain (Long-term Distractor-dense Video Object Segmentation)
Teaching:
-
Advanced Computer Vision (Winter 2020/2021)
-
Advanced Machine Learning (Summer 2019)
-
Advanced Computer Vision (Winter 2018/2019)
Outstanding Reviewer Awards:
Current Students:
-
Arne Hoffhues
-
Jana Zeller
Publications
TarVis: A Unified Approach for Target-based Video Segmentation
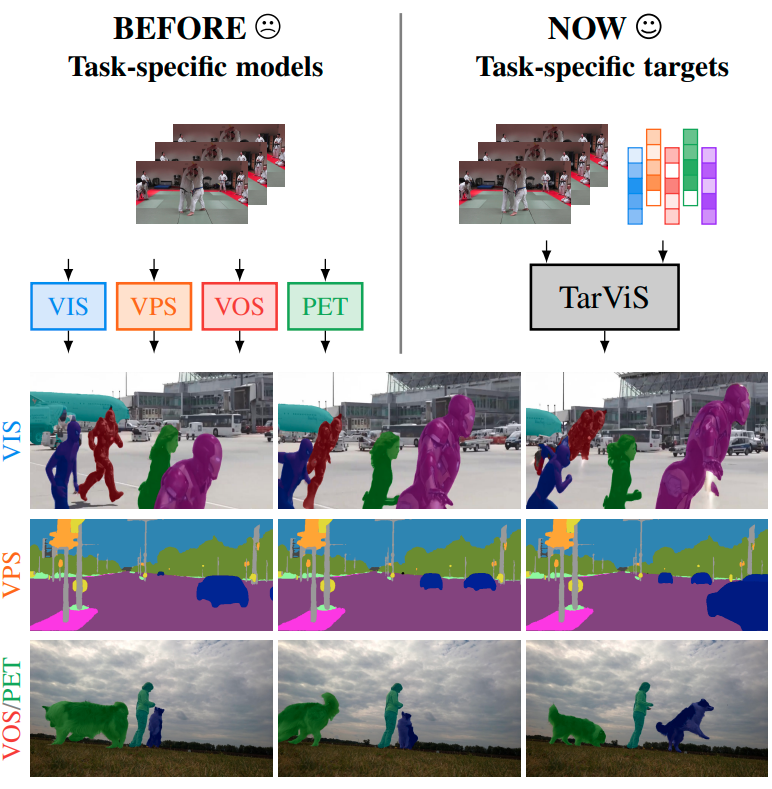
The general domain of video segmentation is currently fragmented into different tasks spanning multiple benchmarks. Despite rapid progress in the state-of-the-art, current methods are overwhelmingly task-specific and cannot conceptually generalize to other tasks. Inspired by recent approaches with multi-task capability, we propose TarViS: a novel, unified network architecture that can be applied to any task that requires segmenting a set of arbitrarily defined 'targets' in video. Our approach is flexible with respect to how tasks define these targets, since it models the latter as abstract 'queries' which are then used to predict pixel-precise target masks. A single TarViS model can be trained jointly on a collection of datasets spanning different tasks, and can hot-swap between tasks during inference without any task-specific retraining. To demonstrate its effectiveness, we apply TarViS to four different tasks, namely Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), Video Object Segmentation (VOS) and Point Exemplar-guided Tracking (PET). Our unified, jointly trained model achieves state-of-the-art performance on 5/7 benchmarks spanning these four tasks, and competitive performance on the remaining two.
» Show BibTeX
@inproceedings{athar2023tarvis,
title={TarViS: A Unified Architecture for Target-based Video Segmentation},
author={Athar, Ali and Hermans, Alexander and Luiten, Jonathon and Ramanan, Deva and Leibe, Bastian},
booktitle={CVPR},
year={2023}
}
BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video

Multiple existing benchmarks involve tracking and segmenting objects in video e.g., Video Object Segmentation (VOS) and Multi-Object Tracking and Segmentation (MOTS), but there is little interaction between them due to the use of disparate benchmark datasets and metrics (e.g. J&F, mAP, sMOTSA). As a result, published works usually target a particular benchmark, and are not easily comparable to each another. We believe that the development of generalized methods that can tackle multiple tasks requires greater cohesion among these research sub-communities. In this paper, we aim to facilitate this by proposing BURST, a dataset which contains thousands of diverse videos with high-quality object masks, and an associated benchmark with six tasks involving object tracking and segmentation in video. All tasks are evaluated using the same data and comparable metrics, which enables researchers to consider them in unison, and hence, more effectively pool knowledge from different methods across different tasks. Additionally, we demonstrate several baselines for all tasks and show that approaches for one task can be applied to another with a quantifiable and explainable performance difference.
» Show BibTeX
@inproceedings{athar2023burst,
title={BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video},
author={Athar, Ali and Luiten, Jonathon and Voigtlaender, Paul and Khurana, Tarasha and Dave, Achal and Leibe, Bastian and Ramanan, Deva},
booktitle={WACV},
year={2023}
}
HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images
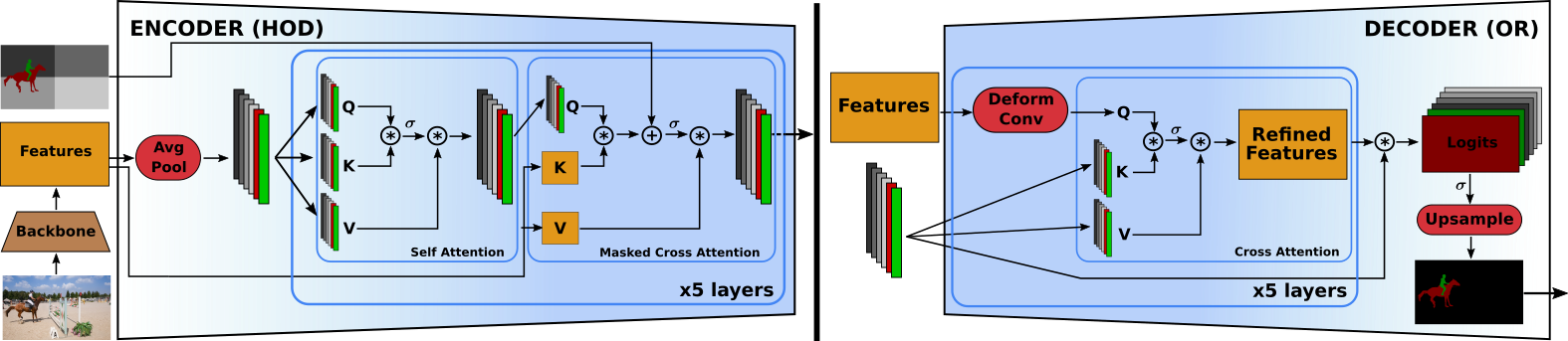
Existing state-of-the-art methods for Video Object Segmentation (VOS) learn low-level pixel-to-pixel correspondences between frames to propagate object masks across video. This requires a large amount of densely annotated video data, which is costly to annotate, and largely redundant since frames within a video are highly correlated. In light of this, we propose HODOR: a novel method that tackles VOS by effectively leveraging annotated static images for understanding object appearance and scene context. We encode object instances and scene information from an image frame into robust high-level descriptors which can then be used to re-segment those objects in different frames. As a result, HODOR achieves state-of-the-art performance on the DAVIS and YouTube-VOS benchmarks compared to existing methods trained without video annotations. Without any architectural modification, HODOR can also learn from video context around single annotated video frames by utilizing cyclic consistency, whereas other methods rely on dense, temporally consistent annotations.
@article{Athar22CVPR,
title = {{HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images}},
author = {Athar, Ali and Luiten, Jonathon and Hermans, Alexander and Ramanan, Deva and Leibe, Bastian},
journal = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR'22)}},
year = {2022}
}
Opening up Open World Tracking

Tracking and detecting any object, including ones never-seen-before during model training, is a crucial but elusive capability of autonomous systems. An autonomous agent that is blind to never-seen-before objects poses a safety hazard when operating in the real world and yet this is how almost all current systems work. One of the main obstacles towards advancing tracking any object is that this task is notoriously difficult to evaluate. A benchmark that would allow us to perform an apples-to-apples comparison of existing efforts is a crucial first step towards advancing this important research field. This paper addresses this evaluation deficit and lays out the landscape and evaluation methodology for detecting and tracking both known and unknown objects in the open-world setting. We propose a new benchmark, TAO-OW: Tracking Any Object in an Open World}, analyze existing efforts in multi-object tracking, and construct a baseline for this task while highlighting future challenges. We hope to open a new front in multi-object tracking research that will hopefully bring us a step closer to intelligent systems that can operate safely in the real world.
@inproceedings{liu2022opening,
title={Opening up Open-World Tracking},
author={Liu, Yang and Zulfikar, Idil Esen and Luiten, Jonathon and Dave, Achal and Ramanan, Deva and Leibe, Bastian and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}
Differentiable Soft-Masked Attention
Transformers have become prevalent in computer vision due to their performance and flexibility in modelling complex operations. Of particular significance is the ‘cross-attention’ operation, which allows a vector representation (e.g. of an object in an image) to be learned by ‘attending’ to an arbitrarily sized set of input features. Recently, ‘Masked Attention’ was proposed in which a given object representation only attends to those image pixel features for which the segmentation mask of that object is active. This specialization of attention proved beneficial for various image and video segmentation tasks. In this paper, we propose another specialization of attention which enables attending over ‘soft-masks’ (those with continuous mask probabilities instead of binary values), and is also differentiable through these mask probabilities, thus allowing the mask used for attention to be learned within the network without requiring direct loss supervision. This can be useful for several applications. Specifically, we employ our ‘Differentiable Soft-Masked Attention’ for the task of Weakly Supervised Video Object Segmentation (VOS), where we develop a transformer-based network for VOS which only requires a single annotated image frame for training, but can also benefit from cycle consistency training on a video with just one annotated frame. Although there is no loss for masks in unlabeled frames, the network is still able to segment objects in those frames due to our novel attention formulation.
HOTA: A Higher Order Metric for Evaluating Multi-object Tracking
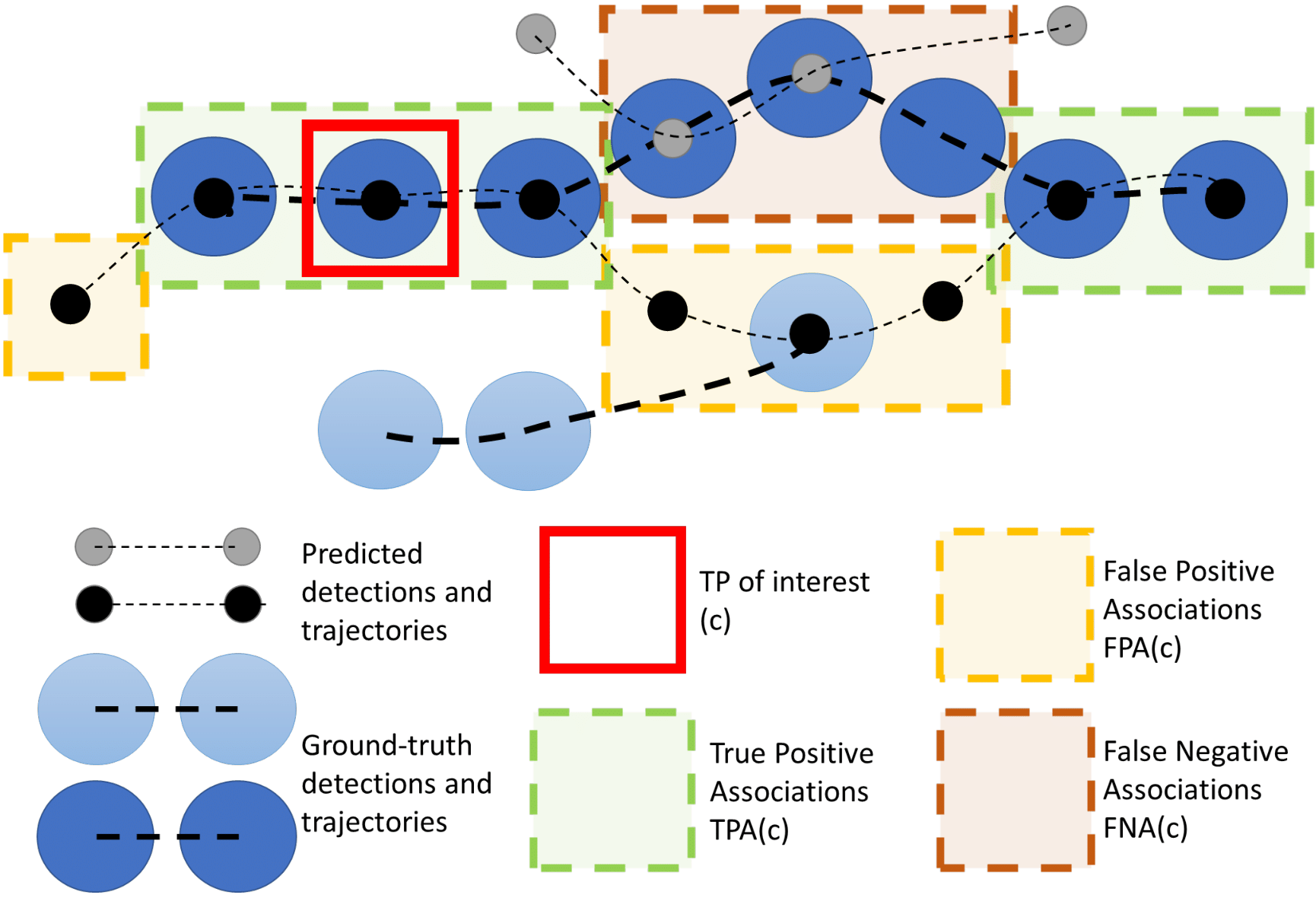
Multi-object tracking (MOT) has been notoriously difficult to evaluate. Previous metrics overemphasize the importance of either detection or association. To address this, we present a novel MOT evaluation metric, higher order tracking accuracy (HOTA), which explicitly balances the effect of performing accurate detection, association and localization into a single unified metric for comparing trackers. HOTA decomposes into a family of sub-metrics which are able to evaluate each of five basic error types separately, which enables clear analysis of tracking performance. We evaluate the effectiveness of HOTA on the MOTChallenge benchmark, and show that it is able to capture important aspects of MOT performance not previously taken into account by established metrics. Furthermore, we show HOTA scores better align with human visual evaluation of tracking performance.
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
Siam R-CNN: Visual Tracking by Re-Detection

We present Siam R-CNN, a Siamese re-detection architecture which unleashes the full power of two-stage object detection approaches for visual object tracking. We combine this with a novel tracklet-based dynamic programming algorithm, which takes advantage of re-detections of both the first-frame template and previous-frame predictions, to model the full history of both the object to be tracked and potential distractor objects. This enables our approach to make better tracking decisions, as well as to re-detect tracked objects after long occlusion. Finally, we propose a novel hard example mining strategy to improve Siam RCNN’s robustness to similar looking objects. The proposed tracker achieves the current best performance on ten tracking benchmarks, with especially strong results for long-term tracking.
@inproceedings{Voigtlaender20CVPR,
title={Siam R-CNN: Visual Tracking by Re-Detection},
author={Paul Voigtlaender and Jonathon Luiten and Philip H. S. Torr and Bastian Leibe},
year={2020},
booktitle={CVPR},
}
Track to Reconstruct and Reconstruct to Track

Object tracking and 3D reconstruction are often performed together, with tracking used as input for reconstruction. However, the obtained reconstructions also provide useful information for improving tracking. We propose a novel method that closes this loop, first tracking to reconstruct, and then reconstructing to track. Our approach, MOTSFusion (Multi-Object Tracking, Segmentation and dynamic object Fusion), exploits the 3D motion extracted from dynamic object reconstructions to track objects through long periods of complete occlusion and to recover missing detections. Our approach first builds up short tracklets using 2D optical flow, and then fuses these into dynamic 3D object reconstructions. The precise 3D object motion of these reconstructions is used to merge tracklets through occlusion into long-term tracks, and to locate objects when detections are missing. On KITTI, our reconstruction-based tracking reduces the number of ID switches of the initial tracklets by more than 50%, and outperforms all previous approaches for both bounding box and segmentation tracking.
@article{luiten2020track,
title={Track to Reconstruct and Reconstruct to Track},
author={Luiten, Jonathon and Fischer, Tobias and Leibe, Bastian},
journal={IEEE Robotics and Automation Letters},
volume={5},
number={2},
pages={1803--1810},
year={2020},
publisher={IEEE}
}
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking

We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixel masks for salient objects in a video sequence and of tracking these objects consistently through time, without any input about which objects should be tracked. Towards solving this task, we present UnOVOST (Unsupervised Offline Video Object Segmentation and Tracking) as a simple and generic algorithm which is able to track and segment a large variety of objects. This algorithm builds up tracks in a number stages, first grouping segments into short tracklets that are spatio-temporally consistent, before merging these tracklets into long-term consistent object tracks based on their visual similarity. In order to achieve this we introduce a novel tracklet-based Forest Path Cutting data association algorithm which builds up a decision forest of track hypotheses before cutting this forest into paths that form long-term consistent object tracks. When evaluating our approach on the DAVIS 2017 Unsupervised dataset we obtain state-of-the-art performance with a mean J &F score of 67.9% on the val, 58% on the test-dev and 56.4% on the test-challenge benchmarks, obtaining first place in the DAVIS 2019 Unsupervised Video Object Segmentation Challenge. UnOVOST even performs competitively with many semi-supervised video object segmentation algorithms even though it is not given any input as to which objects should be tracked and segmented.
@inproceedings{luiten2020unovost,
title={UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking},
author={Luiten, Jonathon and Zulfikar, Idil Esen and Leibe, Bastian},
booktitle={Proceedings of the IEEE Winter Conference on Applications in Computer Vision},
year={2020}
}
Single-Shot Panoptic Segmentation
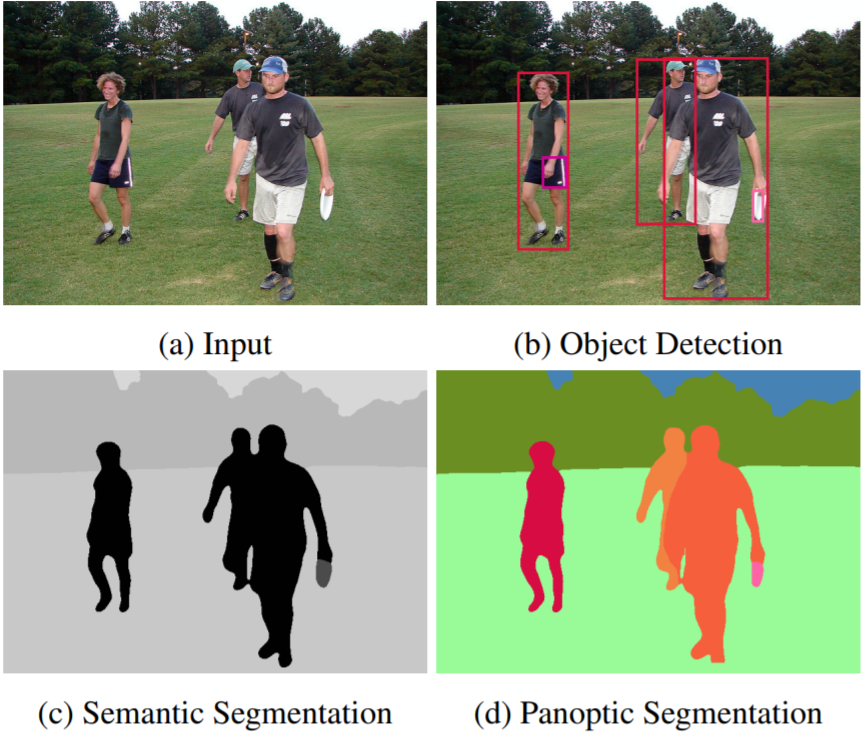
We present a novel end-to-end single-shot method that segments countable object instances (things) as well as background regions (stuff) into a non-overlapping panoptic segmentation at almost video frame rate. Current state-of-the-art methods are far from reaching video frame rate and mostly rely on merging instance segmentation with semantic background segmentation. Our approach relaxes this requirement by using an object detector but is still able to resolve inter- and intra-class overlaps to achieve a non-overlapping segmentation. On top of a shared encoder-decoder backbone, we utilize multiple branches for semantic segmentation, object detection, and instance center prediction. Finally, our panoptic head combines all outputs into a panoptic segmentation and can even handle conflicting predictions between branches as well as certain false predictions. Our network achieves 32.6% PQ on MS-COCO at 21.8 FPS, opening up panoptic segmentation to a broader field of applications.
@article{weber2019single,
title={Single-Shot Panoptic Segmentation},
author={Weber, Mark and Luiten, Jonathon and Leibe, Bastian},
journal={arXiv preprint arXiv:1911.00764},
year={2019}
}
MOTS: Multi-Object Tracking and Segmentation

This paper extends the popular task of multi-object tracking to multi-object tracking and segmentation (MOTS). Towards this goal, we create dense pixel-level annotations for two existing tracking datasets using a semi-automatic annotation procedure. Our new annotations comprise 65,213 pixel masks for 977 distinct objects (cars and pedestrians) in 10,870 video frames. For evaluation, we extend existing multi-object tracking metrics to this new task. Moreover, we propose a new baseline method which jointly addresses detection, tracking, and segmentation with a single convolutional network. We demonstrate the value of our datasets by achieving improvements in performance when training on MOTS annotations. We believe that our datasets, metrics and baseline will become a valuable resource towards developing multi-object tracking approaches that go beyond 2D bounding boxes. We make our annotations, code, and models available at https://www.vision.rwth-aachen.de/page/mots.
» Show BibTeX
@inproceedings{Voigtlaender19CVPR_MOTS,
author = {Paul Voigtlaender and Michael Krause and Aljo\u{s}a O\u{s}ep and Jonathon Luiten and Berin Balachandar Gnana Sekar and Andreas Geiger and Bastian Leibe},
title = {{MOTS}: Multi-Object Tracking and Segmentation},
booktitle = {CVPR},
year = {2019},
}
Large-Scale Object Mining for Object Discovery from Unlabeled Video
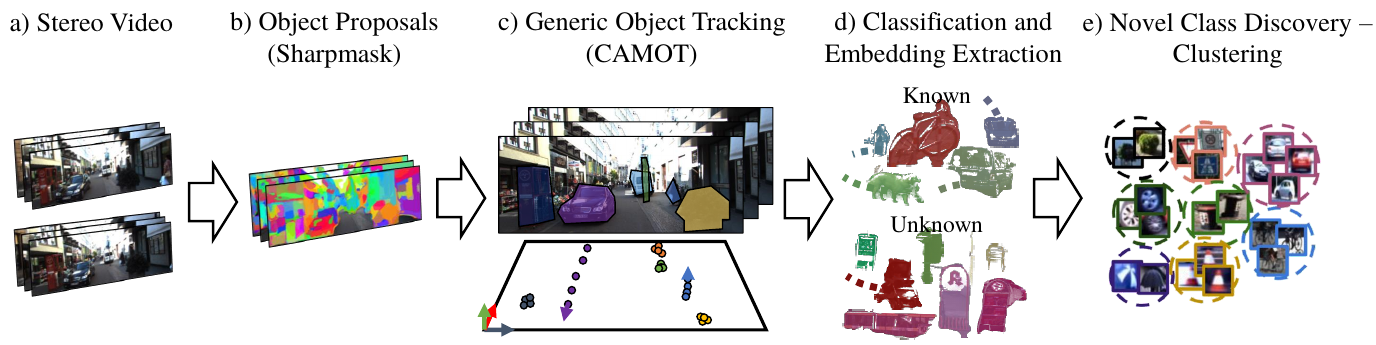
This paper addresses the problem of object discovery from unlabeled driving videos captured in a realistic automotive setting. Identifying recurring object categories in such raw video streams is a very challenging problem. Not only do object candidates first have to be localized in the input images, but many interesting object categories occur relatively infrequently. Object discovery will therefore have to deal with the difficulties of operating in the long tail of the object distribution. We demonstrate the feasibility of performing fully automatic object discovery in such a setting by mining object tracks using a generic object tracker. In order to facilitate further research in object discovery, we will release a collection of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames). We use this dataset to evaluate the suitability of different feature representations and clustering strategies for object discovery.
@article{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Luiten, Jonathon and Breuers, Stefan and Leibe, Bastian},
title = {Large-Scale Object Mining for Object Discovery from Unlabeled Video},
journal = {ICRA},
year = {2019}
}
4D Generic Video Object Proposals

Many high-level video understanding methods require input in the form of object proposals. Currently, such proposals are predominantly generated with the help of networks that were trained for detecting and segmenting a set of known object classes, which limits their applicability to cases where all objects of interest are represented in the training set. This is a restriction for automotive scenarios, where unknown objects can frequently occur. We propose an approach that can reliably extract spatio-temporal object proposals for both known and unknown object categories from stereo video. Our 4D Generic Video Tubes (4D-GVT) method leverages motion cues, stereo data, and object instance segmentation to compute a compact set of video-object proposals that precisely localizes object candidates and their contours in 3D space and time. We show that given only a small amount of labeled data, our 4D-GVT proposal generator generalizes well to real-world scenarios, in which unknown categories appear. It outperforms other approaches that try to detect as many objects as possible by increasing the number of classes in the training set to several thousand.
@inproceedings{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Weber, Mark and Luiten, Jonathon and Leibe, Bastian},
title = {4D Generic Video Object Proposals},
booktitle = {ICRA},
year = {2020}
}
Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge
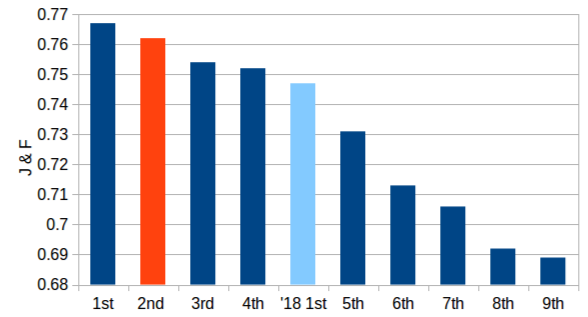
Recently a number of different approaches have beenproposed for tackling the task of Video Object Segmentation(VOS). In this paper we compare and contrast two particu-larly powerful methods, PReMVOS (Proposal-generation,Refinement and Merging for VOS), and BoLTVOS (Box-Level Tracking for VOS). PReMVOS follows a tracking-by-detection framework in which a set of object proposals aregenerated per frame and are then linked into tracks overtime by optical flow and appearance similarity cues. In con-trast, BoLTVOS uses a Siamese architecture to directly de-tect the object to be tracked based on its similarity to thegiven first-frame object. Although BoLTVOS can outper-form PReMVOS when the number of objects to be trackedis small, it does not scale as well to tracking multiple ob-jects. Finally we develop a model which combines bothBoLTVOS and PReMVOS and achieves aJ&Fscore of76.2% on the DAVIS 2017 test-challenge benchmark, re-sulting in a 2nd place finish in the 2019 DAVIS challengeon semi-supervised VOS.
@article{LuitenDAVIS2019,
title={Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge},
author={Luiten, Jonathon and Voigtlaender, Paul and Leibe, Bastian},
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
Video Instance Segmentation 2019: A winning approach for combined Detection, Segmentation, Classification and Tracking.
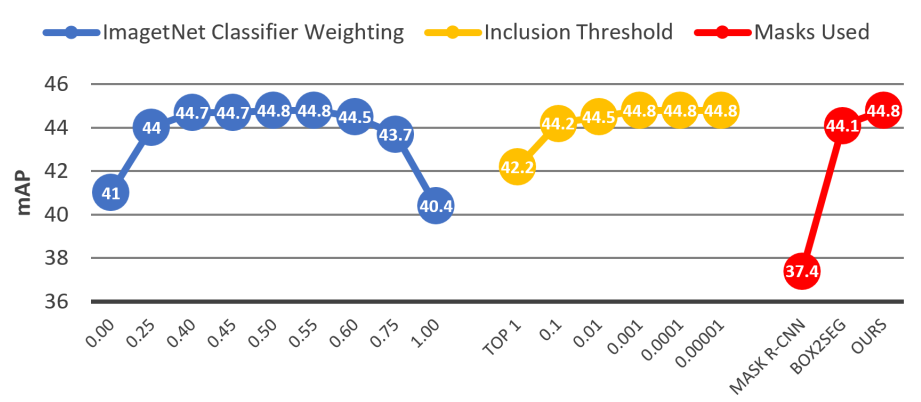
Video Instance Segmentation (VIS) is the task of localizing all objects in a video, segmenting them, tracking them throughout the video and classifying them into a set of predefined classes. In this work, divide VIS into these four parts: detection, segmentation, tracking and classification. We then develop algorithms for performing each of these four sub tasks individually, and combine these into a complete solution for VIS. Our solution is an adaptation of UnOVOST, the current best performing algorithm for Unsupervised Video Object Segmentation, to this VIS task. We benchmark our algorithm on the 2019 YouTube-VIS Challenge, where we obtain first place with an mAP score of 46.7%.
@inproceedings{Luiten19ICCVW_Video,
author = {Jonathon Luiten and Philip Torr and Bastian Leibe},
title = {{Video Instance Segmentation 2019: A winning approach for combined Detection, Segmentation, Classification and Tracking.}},
booktitle = {The 2nd Large-scale Video Object Segmentation Challenge: International Conference on Computer Vision Workshop (ICCVW)},
year = {2019},
}
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge

We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixelmasks for salient objects in a video sequence and of track-ing these objects consistently through time, without any in-formation about which objects should be tracked. Towardssolving this task, we present UnOVOST (Unsupervised Of-fline Video Object Segmentation and Tracking) as a simpleand generic algorithm which is able to track a large varietyof objects. This algorithm hierarchically builds up tracksin five stages. First, object proposal masks are generatedusing Mask R-CNN. Second, masks are sub-selected andclipped so that they do not overlap in the image domain.Third, tracklets are generated by grouping object propos-als that are strongly temporally consistent with each otherunder optical flow warping. Fourth, tracklets are mergedinto long-term consistent object tracks using their temporalconsistency and an appearance similarity metric calculatedusing an object re-identification network. Finally, the mostsalient object tracks are selected based on temporal tracklength and detection confidence scores. We evaluate ourapproach on the DAVIS 2017 Unsupervised dataset and ob-tain state-of-the-art performance with a meanJ&Fscoreof 58% on the test-dev benchmark. Our approach furtherachieves first place in the DAVIS 2019 Unsupervised VideoObject Segmentation Challenge with a mean ofJ&Fscoreof 56.4% on the test-challenge benchmark.
@article{ZulfikarLuitenUnOVOST,
title={UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge},
author={Zulfikar, Idil Esen and Luiten, Jonathon and Leibe, Bastian}
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
Exploring the Combination of PReMVOS, BoLTVOS and UnOVOST for the 2019 YouTube-VOS Challenge
Video Object Segmentation is the task of tracking and segmenting objects in a video given the first-frame mask of objects to be tracked. There have been a number of different successful paradigms for tackling this task, from creating object proposals and linking them in time as in PReMVOS, to detecting objects to be tracked conditioned on the given first-frame as in BoLTVOS, and creating tracklets based on motion consistency before merging these into long-term tracks as in UnOVOST. In this paper we explore how these three different approaches can be combined into a novel Video Object Segmentation algorithm. We evaluate our approach on the 2019 Youtube-VOS challenge where we obtain 6th place with an overall score of 71.5%.
@inproceedings{Luiten19ICCVW_Video,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{Exploring the Combination of PReMVOS, BoLTVOS and UnOVOST for the 2019 YouTube-VOS Challenge}},
booktitle = {The 2nd Large-scale Video Object Segmentation Challenge: International Conference on Computer Vision Workshop (ICCVW)},
year = {2019},
}
BoLTVOS: Box-Level Tracking for Video Object Segmentation

We approach video object segmentation (VOS) by splitting the task into two sub-tasks: bounding box level tracking, followed by bounding box segmentation. Following this paradigm, we present BoLTVOS (Box Level Tracking for VOS), which consists of an R-CNN detector conditioned on the first-frame bounding box to detect the object of interest, a temporal consistency rescoring algorithm, and a Box2Seg network that converts bounding boxes to segmentation masks. BoLTVOS performs VOS using only the first-frame bounding box without the mask. We evaluate our approach on DAVIS 2017 and YouTube-VOS, and show that it outperforms all methods that do not perform first-frame fine-tuning. We further present BoLTVOS-ft, which learns to segment the object in question using the first-frame mask while it is being tracked, without increasing the runtime. BoLTVOS-ft outperforms PReMVOS, the previously best performing VOS method on DAVIS 2016 and YouTube-VOS, while running up to 45 times faster. Our bounding box tracker also outperforms all previous short-term and longterm trackers on the bounding box level tracking datasets OTB 2015 and LTB35.
@article{VoigtlaenderLuiten19arxiv,
author = {Paul Voigtlaender and Jonathon Luiten and Bastian Leibe},
title = {{BoLTVOS: Box-Level Tracking for Video Object Segmentation}},
journal = {arXiv:1904.04552},
year = {2019}
}
PReMVOS: Proposal-generation, Refinement and Merging for Video Object Segmentation
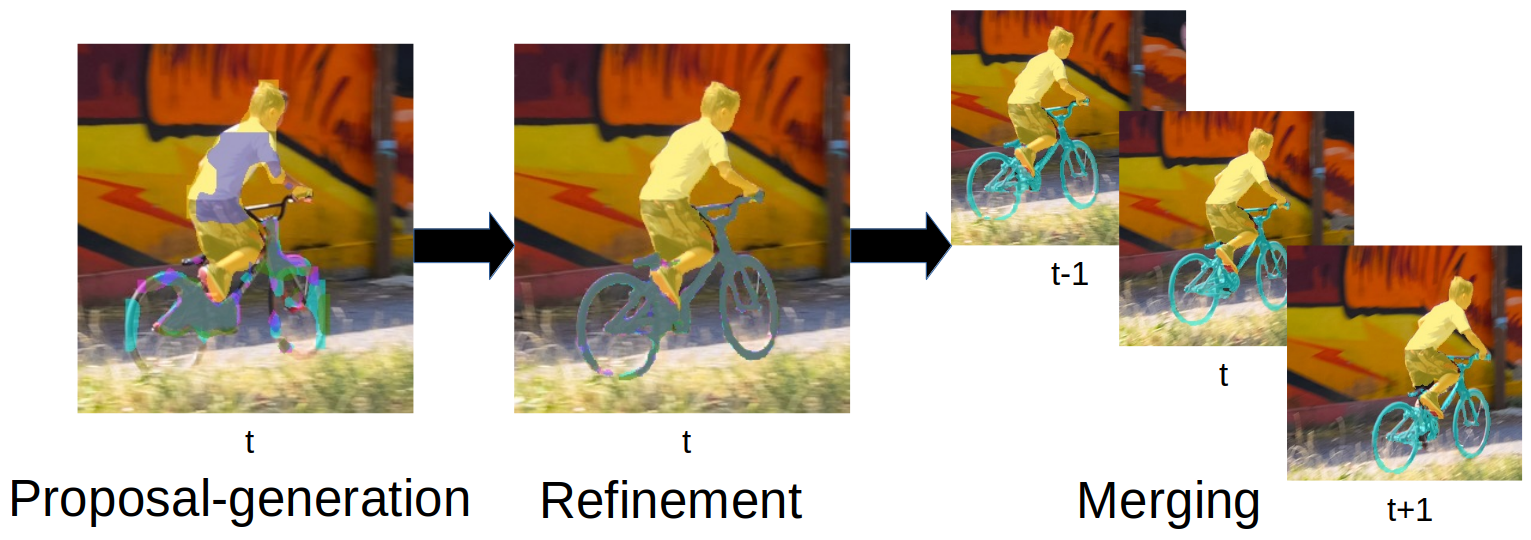
We address semi-supervised video object segmentation, the task of automatically generating accurate and consistent pixel masks for objects in a video sequence, given the first-frame ground truth annotations. Towards this goal, we present the PReMVOS algorithm (Proposalgeneration, Refinement and Merging for Video Object Segmentation). Our method separates this problem into two steps, first generating a set of accurate object segmentation mask proposals for each video frame and then selecting and merging these proposals into accurate and temporally consistent pixel-wise object tracks over a video sequence in a way which is designed to specifically tackle the difficult challenges involved with segmenting multiple objects across a video sequence. Our approach surpasses all previous state-of-the-art results on the DAVIS 2017 video object egmentation benchmark with a J & F mean score of 71.6 on the test-dev dataset, and achieves first place in both the DAVIS 2018 Video Object Segmentation Challenge and the YouTube-VOS 1st Large-scale Video Object Segmentation Challenge.
@inproceedings{luiten2018premvos,
title={PReMVOS: Proposal-generation, Refinement and Merging for Video Object Segmentation},
author={Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
booktitle={Asian Conference on Computer Vision},
year={2018}
}
PReMVOS: Proposal-generation, Refinement and Merging for the DAVIS Challenge on Video Object Segmentation 2018
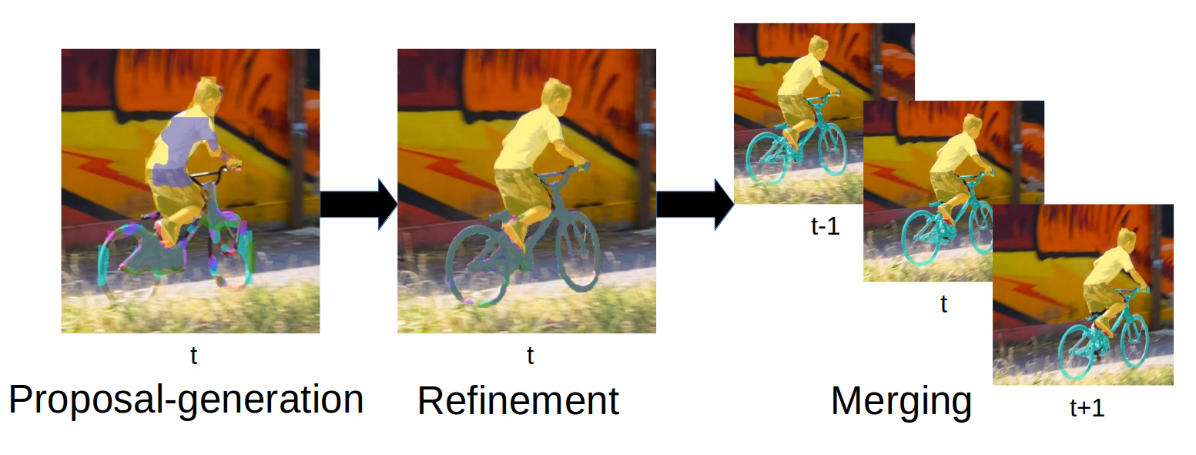
We address semi-supervised video object segmentation, the task of automatically generating accurate and consistent pixel masks for objects in a video sequence, given the first-frame ground truth annotations. Towards this goal, we present the PReMVOS algorithm (Proposal-generation, Refinement and Merging for Video Object Segmentation). This method involves generating coarse object proposals using a Mask R-CNN like object detector, followed by a refinement network that produces accurate pixel masks for each proposal. We then select and link these proposals over time using a merging algorithm that takes into account an objectness score, the optical flow warping, and a Re-ID feature embedding vector for each proposal. We adapt our networks to the target video domain by fine-tuning on a large set of augmented images generated from the first-frame ground truth. Our approach surpasses all previous state-of-the-art results on the DAVIS 2017 video object segmentation benchmark and achieves first place in the DAVIS 2018 Video Object Segmentation Challenge with a mean of J & F score of 74.7.
@article{Luiten18CVPRW,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{PReMVOS: Proposal-generation, Refinement and Merging for the DAVIS Challenge on Video Object Segmentation 2018}},
journal = {The 2018 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2018}
}
PReMVOS: Proposal-generation, Refinement and Merging for the YouTube-VOS Challenge on Video Object Segmentation 2018
We evaluate our PReMVOS algorithm [1]2 on the new YouTube-VOS dataset [3] for the task of semi-supervised video object segmentation (VOS). This task consists of automatically generating accurate and consistent pixel masks for multiple objects in a video sequence, given the object’s first-frame ground truth annotations. The new YouTube-VOS dataset and the corresponding challenge, the 1st Large-scale Video Object Segmentation Challenge, provide a much larger scale evaluation than any previous VOS benchmarks. Our method achieves the best results in the 2018 Large-scale Video Object Segmentation Challenge with a J &F overall mean score over both known and unknown categories of 72.2.
@article{Luiten18ECCVW,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{PReMVOS: Proposal-generation, Refinement and Merging for the YouTube-VOS Challenge on Video Object Segmentation 2018}},
journal = {The 1st Large-scale Video Object Segmentation Challenge - ECCV Workshops},
year = {2018}
}
Towards Large-Scale Video Video Object Mining
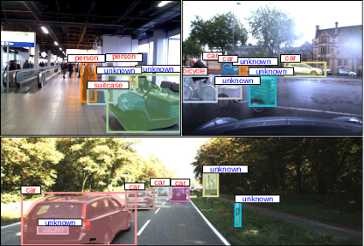
We propose to leverage a generic object tracker in order to perform object mining in large-scale unlabeled videos, captured in a realistic automotive setting. We present a dataset of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames) and propose a method for automated novel category discovery and detector learning. In addition, we show preliminary results on using the mined tracks for object detector adaptation.
@article{OsepVoigtlaender18ECCVW,
title={Towards Large-Scale Video Object Mining},
author={Aljo\v{s}a O\v{s}ep and Paul Voigtlaender and Jonathon Luiten and Stefan Breuers and Bastian Leibe},
journal={ECCV 2018 Workshop on Interactive and Adaptive Learning in an Open World},
year={2018}
}
Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video
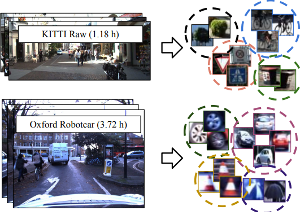
We explore object discovery and detector adaptation based on unlabeled video sequences captured from a mobile platform. We propose a fully automatic approach for object mining from video which builds upon a generic object tracking approach. By applying this method to three large video datasets from autonomous driving and mobile robotics scenarios, we demonstrate its robustness and generality. Based on the object mining results, we propose a novel approach for unsupervised object discovery by appearance-based clustering. We show that this approach successfully discovers interesting objects relevant to driving scenarios. In addition, we perform self-supervised detector adaptation in order to improve detection performance on the KITTI dataset for existing categories. Our approach has direct relevance for enabling large-scale object learning for autonomous driving.
@article{OsepVoigtlaender18arxiv,
title={Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video},
author={Aljo\v{s}a O\v{s}ep and Paul Voigtlaender and Jonathon Luiten and Stefan Breuers and Bastian Leibe},
journal={arXiv preprint arXiv:1712.08832},
year={2018}
}
